- · 《低碳世界》栏目设置[05/29]
- · 《低碳世界》收稿方向[05/29]
- · 《低碳世界》投稿方式[05/29]
- · 《低碳世界》征稿要求[05/29]
- · 《低碳世界》刊物宗旨[05/29]
一、稿件要求: 1、稿件内容应该是与某一计算机类具体产品紧密相关的新闻评论、购买体验、性能详析等文章。要求稿件论点中立,论述详实,能够对读者的购买起到指导作用。文章体裁不限,字数不限。 2、稿件建议采用纯文本格式(*.txt)。如果是文本文件,请注明插图位置。插图应清晰可辨,可保存为*.jpg、*.gif格式。如使用word等编辑的文本,建议不要将图片直接嵌在word文件中,而将插图另存,并注明插图位置。 3、如果用电子邮件投稿,最好压缩后发送。 4、请使用中文的标点符号。例如句号为。而不是.。 5、来稿请注明作者署名(真实姓名、笔名)、详细地址、邮编、联系电话、E-mail地址等,以便联系。 6、我们保留对稿件的增删权。 7、我们对有一稿多投、剽窃或抄袭行为者,将保留追究由此引起的法律、经济责任的权利。 二、投稿方式: 1、 请使用电子邮件方式投递稿件。 2、 编译的稿件,请注明出处并附带原文。 3、 请按稿件内容投递到相关编辑信箱 三、稿件著作权: 1、 投稿人保证其向我方所投之作品是其本人或与他人合作创作之成果,或对所投作品拥有合法的著作权,无第三人对其作品提出可成立之权利主张。 2、 投稿人保证向我方所投之稿件,尚未在任何媒体上发表。 3、 投稿人保证其作品不含有违反宪法、法律及损害社会公共利益之内容。 4、 投稿人向我方所投之作品不得同时向第三方投送,即不允许一稿多投。若投稿人有违反该款约定的行为,则我方有权不向投稿人支付报酬。但我方在收到投稿人所投作品10日内未作出采用通知的除外。 5、 投稿人授予我方享有作品专有使用权的方式包括但不限于:通过网络向公众传播、复制、摘编、表演、播放、展览、发行、摄制电影、电视、录像制品、录制录音制品、制作数字化制品、改编、翻译、注释、编辑,以及出版、许可其他媒体、网站及单位转载、摘编、播放、录制、翻译、注释、编辑、改编、摄制。 6、 投稿人委托我方声明,未经我方许可,任何网站、媒体、组织不得转载、摘编其作品。
480块GPU跑出万亿参数!阿里推“低碳版”AI大模型
作者:网站采编关键词:
摘要:智慧之物(公众号:zhidxcom) 作者|鑫源 编辑|墨影 智物6月25日报道,今日,阿里巴巴法学院发布巨模M6“低碳版”,大幅降低万亿参数超大模型训练能耗这是世界上第一次。 据悉,达摩
智慧之物(公众号:zhidxcom)
作者|鑫源
编辑|墨影
智物6月25日报道,今日,阿里巴巴法学院发布巨模M6“低碳版”,大幅降低万亿参数超大模型训练能耗这是世界上第一次。
据悉,达摩学院团队仅使用了 480 张 NVIDIA V100 GPU 来训练多模态多模态模型 M6,其规模是人类神经元的 10 倍。
相比英伟达、谷歌等海外公司实现的万亿级参数规模,阿里“低碳版”M6能耗降低80%以上,效率提升近11倍。
1、M6连续三跃进步,万亿、商用、低功耗
达摩院今年发布的M6巨模实现了“三连跳”今年正在进行中。
1月份实现百亿参数,2月份实现千亿参数。 5月,全球首次大幅降低万亿参数超大模型的训练能耗。
本次达摩学院训练了一个万亿参数模型M6,仅使用了480张V100 32G GPU,节省了80%以上的计算资源,训练效率提升了近11倍。
相比之下,英伟达此前实现了万亿级参数,使用了3072个A100 GPU; Google 实现了一个包含 1.6 万亿个参数的大型模型,并使用了 2048 个 TPU。
M6拥有超越传统AI的认知和创造力。擅长绘画、写作、问答,在电子商务、制造业、文学艺术等诸多领域具有广阔的应用前景。
比如在应用效果方面,OpenAI DALL·E生成的图片分辨率为256×256,M6将图片分辨率提高到1024×1024。
< img src="http://p2.qhimgs4.com/t01f8ac21207ad6f2b8.jpg">不仅如此,M6还是国内第一款商业化的多模态大模型。
例如,经过一段时间的试用,M6将正式被聘为阿里巴巴新制造平台犀牛智造的AI助理设计师。
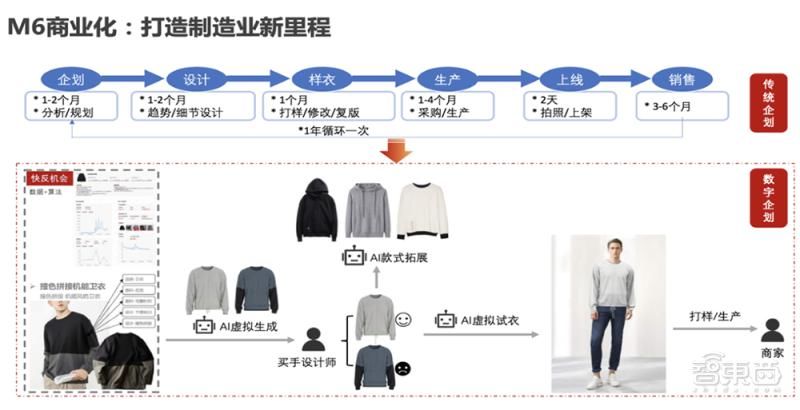 ▲M6参与新服装设计流程图
▲M6参与新服装设计流程图
结合快速设计趋势、试穿效果模拟,有望大大缩短快时尚新衣的设计周期。
 ▲M6生成的高清服装设计
▲M6生成的高清服装设计
M6也被应用到支付宝和淘宝参与跨模式搜索、文案、形象设计等平台。
以文案为例,给M6一张产品图片,它可以直接生成对应的文案,而且模型参数尺度越大,生成的文字的用词就越准确。
 ▲不同比例M6模型生成的风衣图片描述文案
▲不同比例M6模型生成的风衣图片描述文案
再举个例子,当消费者在淘宝搜索中输入特殊需求,而该需求通常不是商家在商品名称和描述中写明时,M6可以直接将搜索文字与商品图片关联起来,快速找到可能满足消费者需求的商品.
 ▲M6搜索“日式凹凸咖啡杯”
▲M6搜索“日式凹凸咖啡杯”
2.采用MoE模型,解决大规模模型训练的挑战
大规模模型研究的一个主要技术挑战是,当模型扩展到千亿级及以上规模时,将难以把它放在一台机器上。
如果使用模型+流水线并行分布式策略,一方面代码实现比较复杂,另一方面由于前向和反向传播的FLOPs太高,训练效率为该模型将非常低。很难在有限的时间内训练足够的样本。
阿里M6团队从开发大型模型开始就特别关注GreenAI,即提高超大规模预训练模型的资源利用率和训练效率,并沉淀大规模模型高效训练的能力。这样,更多的人可以以更低的成本训练或应用大型模型。
针对大模型普遍存在的计算能力成本高的问题,达摩学院联合阿里云机器学习PAI平台、EFLOPS计算集群等团队对MOE(Mixture-of -专家)框架和创造性通过专家并行策略,单个模型的承载能力得到了极大的扩展。
同时,通过加速线性代数、混合精度训练、半精度通信等优化技术,达摩院团队大幅提升万亿模型的训练速度,有效降低在效果接近无损的前提下的训练成本。需要计算资源。
团队在基本的 MoE 策略的基础上,更详细地探索了 MoE 的预训练模型中的各种超参数对模型收敛速度和精度的影响,包括top-k,容量对负载均衡的影响,负载均衡本身对效果的影响。基于这一系列的观察,他们提出了Expert Prototyping的方法,采用分组MoE的形式,使得不同组的MoE可以在不改变参数尺度的情况下增加模型的表达空间。
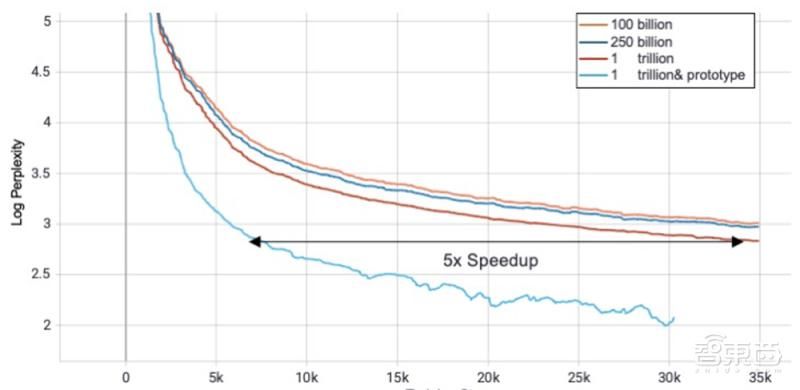
他们观察到,在不同尺度的模型上,分组的 MoE 可以取得比基线更好的结果。与单组交换机路由串行实现相比,分组MoE可以达到更好的加速效果。团队发现他在更大规模模型上的优势会变得更大,如下图:
 在机器上另一方面,M6团队最终采用了在Hippo混合集群中建模的方案,使用480单卡NVIDIA? V100-32GB,通讯是100Gb? RoCEv2 RDMA网络网络,在XDL上提交任务,成功完成Trillion模型训练。
在机器上另一方面,M6团队最终采用了在Hippo混合集群中建模的方案,使用480单卡NVIDIA? V100-32GB,通讯是100Gb? RoCEv2 RDMA网络网络,在XDL上提交任务,成功完成Trillion模型训练。
未来,M6团队将进一步探索纵向扩展参数的规模,寻求模型深度和宽度之间的最佳平衡。
文章来源:《低碳世界》 网址: http://www.dtsjzzs.cn/zonghexinwen/2021/0626/1411.html